Sometimes programmers have to deal with larger than usual text files. Examples are log files or XML dumps of databases. For my tests, I used a dump of the English Wikipedia in XML format. This file is 48 gigabytes in size and as I found out only today contains 789,577,286 lines of text.
If you google for “large text viewer” you get quite a few hits, but many of these are not what they advertise.
Others kind of work but have various shortcomings, e.g. Large Text File Reader which allows you to only display the first n lines of a file. But don’t try to enter too large a number because it will then just hang. Then there is Log Expert which was suggested by this answer on StackOverflow but apparently tries to load the whole file into memory, nearly crashing my Windows installation.
I found the following viewers which seem to work:
LTFViewer from the now defunct swiftgear.com site (Link therefore goes to archive.org). This works but seems to be rather slow in reading the file. Closed it after about an hour when it had read about 200 million lines.
glogg which is a log file viewer with searching and filtering. It’s multi platform which usually means that the Windows version is barely usable. Glogg is not too bad on this account. It took quite a while loading the file which ran in the background. Unfortunately while it is loading the file, you cannot browse it. It only displays the first page, scrolling is impossible. You can use the filter function though. It took about one hour to read the 48 GB file using 1 GB of memory in the process. Once it has loaded it, it supports e.g. incremental search, which, in a file of this size takes quite a while.
Another option is a file viewer written in JavaScript at www.readfileonline.com. I had my doubts about this but since it works locally and browses the file in batches of a given size, it can be very fast. It even has a search function, but of course that one has limits when talking about a file of 48 gigabytes.
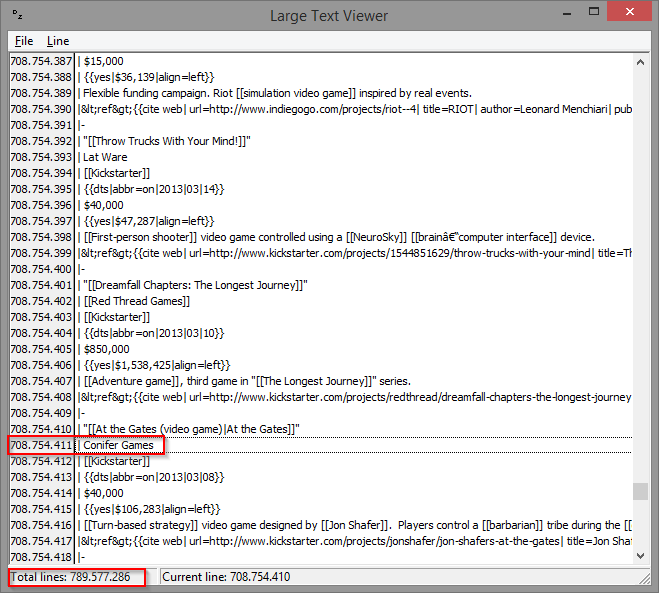
Yours truly also wrote such a tool, back when I received a huge XML file from a customer, also a database dump, and had to resort to Linux and the less command line tool to view it. dzLargeTextViewer doesn’t have many features. It theoretically allows you to display files up to MaxInt64 lines. I have tested it with the aforementioned Wikipedia dump. The first version ran out of memory after around 75 million lines. The second version used 1 GB of memory and could index about 300 million lines. The third version now has read all nearly 790 million lines and displays them, using only 3.5 MB of memory. To achieve that, it created a 6 GB index file. It stores that file as <Filename>.LineIndex so it can be reused when the same file is opened again. My tool assumes ansi strings, though, while glogg reads the file as UTF-8.